2013年7月 初版
会場: 天文データセンター
第1部のC言語の講習の内容をみて,多くの方が「面倒さ」というものを感じた事と 思います. 第2部では C++ をうまく使う事で,このような「面倒さ」を回避し, 本質的な部分に集中できるコーディングより, 科学研究で求められるソフトウェア品質をさらに高めていく手法を学びます.
第1部では,C言語でのプログラミングは「我々の目的から遠い」 という事を多くの方が感じたと思います. 特に,文字列や配列などの「メモリ」の扱いが繁雑すぎる上に, メモリ保護が十分ではないのです. ソースコードが大きくなると,メモリリークを起こしてしまう危険性が 高くなり,メモリリークのバグが見つかった場合, コードの品質によっては修正が非常に難しくなる事もあります.
このような問題を解決する事を1つの目的として,C++が作られました. 具体的には「クラス」や C++ 標準ライブラリがそれらに対する解で, ヒープメモリの自動開放や,ヒープメモリのある程度の自動確保が可能に なっています. しかし,スクリプト言語のレベルでメモリ管理が自動化されているかというと, そうではありません. APIもスクリプト言語に比べると十分ではなく, 我々の目的からは依然として距離があると言わざるを得ないものです. この原因は,C++ は C と同様に「汎用性」を重視して設計されているためです. つまり,C++ 標準ライブラリで提供されるのは「汎用部品」であり, それを使って「実用的」なものを作るのはプログラマの手に委ねられているのです. 結局のところ,C++ は C よりは楽になるが それなりの手間がかかる,という事になります.
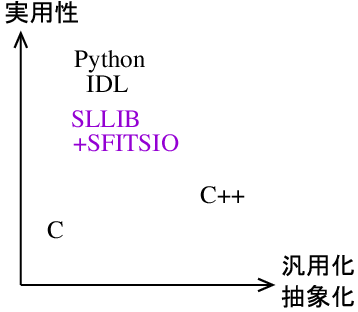
さらに C++ にはこのような状況に加え, 「C++標準ライブラリ特有の作法」の習得をプログラマに要求する事もあり, 結局のところ C++ は敬遠されているのが実情です. 実際,この業界では「実用部品」を備えるスクリプト言語 (例: Python,IDL) がデータ解析の主力になってきています. しかし,C++ の処理速度は圧倒的に高く,その性能が どうしても必要になる事がありますし,それは 研究の効率にも影響を与えます. となると,もっと目的に近い C++ 環境が使えれば… と考えるのは自然な事です.
SLLIB・SFITSIO は,まさにそれを狙った C++ のライブラリで, スクリプト言語のような,自動メモリ管理機能と実用的なAPIを C++ 環境上に 提供します. 言語を切り替える事なく,実用的なAPIが使えて,最高の処理速度を狙う事がで きるというわけです.
基本的には C++ は C の上位互換ですが, 微妙に変わっている部分がありますので,以下でみていきます.
#include <iostream>
int main()
{
std::cout << "Hello World\n";
return 0;
}
というコードが一般的な C++ の教科書には書かれますが,これは無視して かまいません.次の C の場合と同じコードで全く問題ありません.
#include <stdio.h>
int main()
{
printf("Hello World\n");
return 0;
}
○実習1○
次のように,コンパイルして「Hello World」を出力するプログラムを 作成してください.
$ g++ -O -Wall hello.cc -o hello
多くの処理系では,Cの場合は
define NULL ((void*)0)
と定義されています.しかし,C++の場合は
define NULL (0)
と定義されます.
C++で NULL が 0 となっている理由は,
C++の場合,ポインタ変数の型のチェックがCよりも厳格になっているからです.
例えば,2つのポインタ変数「char *ptr0;」
「void *ptr1;」があり,
「ptr0 = ptr1;」とした時は
エラーになります.しかし,0 だけは
「どこでもないアドレス」と定義しているので,
「ptr0 = 0;」はエラーになりません.
そういうわけで,C++では NULL は 0
になっているのです.
さて,C++では,クラスの持つメンバ関数は, 同名でも引数が異なる場合があります. 例えば,
int foo( int a ); int foo( char *p );
のような場合です.
ここで,「hoge.foo(NULL)」あるいは
「hoge.foo(0)」とすると,一体どちらの関数を使いたいのか
コンパイラが理解できないという事態になります.
この場合,NULL や 0 を使う場合にはキャストして,
型を明示的に示す事が必要です.すなわち,
hoge.foo((char *)NULL);
hoge.foo((int)0);
のようにしなければなりません.
というわけで,C++では,
「NULL や 0 を使う時はキャストする」と覚えておけば
間違いないでしょう.
C言語でも stdbool.h
を include すれば,真理値型が使えました.
真理値型は,2つの値(true または false)
をとります.
C++ では,はじめから真理値型が使えるので,ヘッダファイルの include は 不要です.
Cで書かれたライブラリも C++ から問題なく使う事ができます. ポイントは次のとおりです.
C で書かれたライブラリのヘッダファイルをみて,
#ifdef __cplusplus
extern "C" {
#endif
という部分があるかをチェックし,あればそのまま #include <….h>
すればOKです.
もし無ければ,自分のコードに
extern "C" {
#include <….h>
}
と書きます.簡単ですね.
ネームスペース(名前空間)は,別々の人が同じ名前の関数や型を作ってしまうと困った事になる, という問題を回避するもので,要するにカテゴリ名のようなものです. 例えば,
namespace hoge
{
int calc( double a )
{
:
:
}
}
と書けば,関数 calc() はネームスペース hoge に属する,という事になります.
そしてこの関数を使う場合は,「hoge::calc(v);」のように書き
ます.
C++標準ライブラリでは「std」,
SLLIB では「sli」というネームスペースを使っています.
少し前にでてきた「Hello World」の例では,
「std::cout」と書きました.
この「std::」は「stdというネームスペースの」という意味です.
ネームスペースが std のものしか使わない,という場合は,
using namespace std;
と書けば,それ以降では「std::」を省略する事ができます.
ただし,規模の大きいプログラムの場合は混乱の元ですので
「using namespace」は使わない方が良いでしょう.
なお,C++環境では,C標準関数は名前の無い
「グローバルネームスペース」
に属します.例えば,数学関数の sin(),cos()
は C++ においても math.h を include すれば使えますが,
厳密には,「::sin()」,「::cos()」と記述します.
同様に,stdio.h の printf() 関数も,
厳密には「::printf(…)」と書きます.
ネームスペースを使った関数の定義方法と,利用方法を次のコードで示します. これは,第1部で登場した安全性を高めた acos() 関数を namespace を使って実装しなおしたものです.
#include <stdio.h>
#include <math.h>
namespace safe /* ネームスペース「safe」の開始 */
{
inline static double acos( double x )
{
const double d = 0.0000001; /* 許容する誤差 */
if ( x < -1.0 ) {
if ( x < -1.0 - d ) ::fprintf(stderr,"[WARNING] %s: arg is %.15g\n",
__PRETTY_FUNCTION__, x);
x = -1.0;
}
else if ( 1.0 < x ) {
if ( 1.0 + d < x ) ::fprintf(stderr,"[WARNING] %s: arg is %.15g\n",
__PRETTY_FUNCTION__, x);
x = 1.0;
}
return ::acos(x); /* 「::」を書き忘れると自身を呼び出してしまうので注意 */
}
} /* ネームスペース「safe」の終了 */
int main()
{
::printf("acos = %g\n", ::acos(1.1));
::printf("safe acos = %g\n", safe::acos(1.1));
return 0;
}
○実習2○
上記のコードをコンパイルし,動作を確認してください. さらに,main() 関数内のグローバルネームスペースに関する指定が省略できる事を確認してください.
C++ では,同じ関数名で引数が異なる複数の関数を定義する事ができます.
C言語ではこれができなかったので,例えば
数学関数の正弦関数は,double版では sin(),
float版では sinf() のように,それぞれ別の名前になっていました.
C++ であれば,このような場合に関数名を同じ名前に揃える事ができ,
これを「関数のオーバロード」と言います.
参考:
C言語でも
tgmath.h を include すれば
同じ関数名で float版,double版の関数を使う事ができます.
これはマクロで実現されています.
◎課題1◎
safe::acos() について float 版を追加してください
(定数 d については変更不要).
main() 関数を次のように変更してコンパイルし,動作を確認してください.
int main()
{
::printf("acos = %g\n", ::acos(1.1));
::printf("safe acos = %g\n", safe::acos((double)1.1));
::printf("safe acos = %g\n", safe::acos((float)1.1));
return 0;
}
ソートに代表される各種アルゴリズムを扱う関数を書いた時, C言語では,引数の型に応じて double 用の関数,float 用の関数, といったように,複数の関数を用意する必要がありました. C++ の「テンプレート」という機能を使うと, そのような複数の関数を1つにまとめる事ができます.つまり, 任意の型の引数をとる関数が作れるというわけです.
次の例は,double型の配列,float型の配列の合計値を計算するコードです.
#include <stdio.h>
#include <math.h>
template <class datatype>
inline static double get_sum( const datatype vals[], size_t n )
{
double sum = 0;
size_t i;
for ( i=0 ; i < n ; i++ ) sum += vals[i];
return sum;
}
int main()
{
double v0[] = {10.1, 20.1, 30.1, 40.1, 50.1, 60.1, 70.1, 80.1, 90.1, 100.1};
const size_t n_v0 = sizeof(v0) / sizeof(*(v0));
float v1[] = {1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1, 9.1, 10.1};
const size_t n_v1 = sizeof(v0) / sizeof(*(v0));
printf("sum of v0 = %g\n", get_sum(v0,n_v0));
printf("sum of v1 = %g\n", get_sum(v1,n_v1));
return 0;
}
テンプレートの書き方は非常に簡単で,関数を定義する前に
「template <class datatype>」
と書いて,あとは double や float のかわりに「datatype」
を使って関数の内容を書くだけです.
複数の任意型を使いたい場合は,最初の部分を
template <class datatype1, class datatype2>
のように書くだけです.これで,関数内のコードで,
「datatype1」「datatype2」
の2つの型が使えるようになります.
○実習3○
上記のコードをコンパイルし,動作を確認してください.
◎課題2◎
get_mean」を作成し,
平均値を算出してください.
C言語の構造体ではメンバになれるものは,変数だけでした. C++ の「クラス」は,C言語の構造体を拡張し, 様々な機能を付加したもので,C++ で最も重要な言語拡張です. この後の講義・実習では,じっくりとクラスの使い方をみていきますので, ここでは概要だけ紹介しておきます.
C++の「クラス」では,次のような機能拡張が行なわれました:
「クラスを使う」のと「クラスを作る」のとでは, 難易度が全く異なります. この講習では難易度が低い「クラスを使う」事のみをとりあげます. クラスを使う事で,クラスというものがどういうものなのかが, だんだんわかってくるようになります.
なお,クラスの作成はあまりに難しく奥が深いので, 一般の天文学者は手を出さない方が良いでしょう. それよりは,「クラスを使う」ところまでの技術で,しっかり 正しく動くものを作れるようになる方が大事と思います. クラスの作成というのは,技術の選択肢を爆発的に増やしますが, 目的を理解せずに技術を使ってしまい,むしろ品質を低下させている事例も多くみかけます. 第1部でもとりあげましたが,技術は「もて遊ぶ」とロクな事にならないのです.
注意していただきたのは,「クラス」と「ネームスペース」とは 明確に異なる概念だという事です. 時々「メンバ関数しか持たないクラス」を作る方を見かけますが, その方はクラスの目的を理解していない,と言えます. 関数をグループ化したいなら,クラスではなくネームスペースを使うべきなのです.
参照は「エイリアス」とも呼ばれ, 変数(クラスの場合はオブジェクト)の別名を定義するための単純な仕組みです. 変数の別名はマクロを使って
#define v value
のようにも書けますが,これは文字列の置き換え(プリプロセス)を行なってから コンパイルを実行する事になります. 参照はマクロとは異なり,その実装に変数のアドレスが利用されます. 例えば,
double value = 10;
double &v = value;
printf("値 = %g\n",value);
printf("値 = %g\n",v);
と書くと,2つの printf() 関数はどちらも同じ値を表示します.
つまり,「value」「v」のどちらで
アクセスしても同じという事です.
この時,「v」が保持しているメモリ上の値は,
「value」のアドレスです.しかし,コード上に「v」
と書くと「value」の値にアクセスするのです.
ここで「&」記号がでてきて,
「またか」と思われるかもしれません.
そうです.また1つの記号を別の意味に使ってしまう事になるのです.
紛らわしいですが,慣れるしかありません.
なお,参照「v」の型は何でしょう?
答えは「double &」です.
スペースに騙されないようにしましょう.
ところで,参照など無くても「ポインタ変数で十分では?」と思われるかもしれ ません. 確かに参照は無くても困らないものですが, クラスを使う場合には参照を使う方がコードが見やすくなるという利点があります. よく使われるのは,関数の引数についての入力・出力を明確化させるために, 参照を使う方法です:
static int foo( const hoge_class &in, hoge_class *out )
{
:
:
}
int main()
{
hoge_class a, b;
:
:
foo( a, &b );
:
関数 foo() の定義では,
1つめの引数は読み取りのみ,2つめの引数は書き換わる事がある事がわかります.
この時,main() 関数での foo() の呼び出し部分をみてみると,
感覚的に a は入力で b は結果取得である事がわかります.
これがもし両方ともポインタ変数の場合,この部分は
「foo( &a, &b );」
となってしまい,コードから情報量が減ってしまいます.
どのように使うべき技術を絞っていくかというのは難しい問題で, この場合のように,可読性の向上を目的とした「ワンパターン」を実践するために, 技術を追加した方が良いという事もあります.
参照の使い方は,パターンが決まっています. どのような時に使うべきかは,この講習会をすべて受講すれば わかるようになります.
○実習4○
上記のコードを参考に,double型の変数について参照を作成し, 動作確認を行なってください.
Cの場合と同様,C++にも「標準ライブラリ」というものがあります. この C++ 標準ライブラリには,ストリーム(ファイルのI/O)や 各種アルゴリズムを扱う API がありますが, ストリームはかなり趣味が悪いのでこの講習会では取り上げません. 各種アルゴリズムについてもコードを組むにあたっては直感的でない部分も多い のですが,かなり高性能ですのでここで少しだけ取り上げる事にします.
std::vector は任意の型の1次元配列を扱うための
テンプレートクラスです.
配列は常にヒープメモリから取得されるので,
巨大な配列を扱う事ができます.また,
スコープを抜けると使っていたメモリが自動的に開放されますので,
メモリリークの心配がありません.
例を見ていきましょう.
#include <stdio.h>
#include <vector>
int main()
{
/* float型の配列オブジェクト */
std::vector<float> array;
size_t i;
/* 10個分を確保 */
array.resize(10);
/* 配列へ代入 */
for ( i=0 ; i < array.size() ; i++ ) {
array[i] = i;
}
/* 配列の内容を表示 */
for ( i=0 ; i < array.size() ; i++ ) {
printf("[%g]",array[i]);
}
printf("\n");
return 0;
}
「array」というのが,std::vectorクラスの
オブジェクト(インスタンス)です.
クラスのオブジェクトというのは,スクリプト言語の変数と非常に良く似ていて,
中の実装はなんだか複雑な事になっているけれど,
使い方を知っていれば簡単に使えてしまう,変数の豪華版のようなものです.
とにかく,「オブジェクト.resize(欲しい数)」と書けば
配列の大きさをいつでも変更できるし,
「オブジェクト.size()」と書けば現在の配列の大きさを取得できるのです.
要素へのアクセスは普通の配列と同様に [i] と書けばOK.
簡単ですね.
なお,[i] での要素へのアクセスでは,バッファの境界チェックはありませんので,バッファオーバーフローに対する保護がありません.
[i] のかわりに .at(i) でアクセスすれば,
バッファの境界チェックが効き,範囲外へのアクセスがあった場合は
例外を投げてきます(プログラムはabortします).
std::vector はスクリプト言語のように [i] による
アクセスでメモリ領域が自動確保されるわけではありません.
○実習5○
上記のコードの動作確認を行なってください.
std::stack は,データの出し入れを
FILO(ファースト・イン、ラスト・アウト)で行なうためのテンプレートクラスです.
std::vectorと同様,
スコープを抜けると使っていたメモリが自動的に開放されますので,
メモリリークの心配がありません.
例を見ていきましょう.
#include <stdio.h>
#include <stack>
int main()
{
/* float型のスタックオブジェクト */
std::stack<float> my_stack;
size_t i;
/* スタックへ値をつめていく */
for ( i=0 ; i < 10 ; i++ ) {
my_stack.push(i);
}
/* スタックから取り出して,その内容を表示 */
while ( my_stack.empty() == false ) {
printf("[%g]",my_stack.top()); /* スタックの先頭 */
my_stack.pop(); /* 先頭を削除 */
}
printf("\n");
return 0;
}
「オブジェクト.push(値)」で値を積んでいき,
「オブジェクト.top()」で積まれた一番上の値を読み取ります.
「オブジェクト.pop()」で一番上の要素を削除します.
メモリは自動的に確保されるので,非常に簡単です.
○実習6○
上記のコードの動作確認を行なってください.
C++標準ライブラリで最も優れている点は,ソートのような
アルゴリズムを提供する関数の性能が非常に高いという事です.
ここではそのうちの1つ,クイックソートを行なう関数
std::sort()
を取り上げます.
クイックソートは
一般的に最も高速と言われる「安定ではないソート」の手法です.
C言語の標準ライブラリ(LIBC)にも
qsort() という関数
(ヘッダはstdlib.h)がありますが,C++の std::sort()
の方がずっと高速に動作します.この速度差の原因は,qsort()
での比較関数の呼び出しのオーバヘッドです.
std::sort() にはそれが無いから速いのです.
使い方については,double や float のようなプリミティブ型の場合は
std::sort() の方が簡単です.
例えば,100 個の配列要素がポインタ変数 p で管理されている場合,
std::sort(p, p + 100);
と書くだけでソートができてしまいます
(qsort() の場合,
どんな場合でも比較関数をプログラマが作る必要があります).
std::sort() の第1引数は「配列の先頭要素のアドレス」,
第2引数は「配列の最後の次の要素のアドレス」を指定します.
次に,qsort(), std::sort() それぞれの
性能をテストするためのコードを示します.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <vector>
#include <algorithm> /* std::sort() を使うために必要 */
/* LIBC の qsort() に与える比較関数 */
static int compar_float( const void *_p0, const void *_p1 )
{
const float *p0 = (const float *)_p0;
const float *p1 = (const float *)_p1;
if ( *(p0) < *(p1) ) return -1;
else if ( *(p1) < *(p0) ) return 1;
else return 0;
}
int main()
{
const size_t n_elements = 10000000; /* 配列の個数 */
std::vector<float> array; /* float型の配列オブジェクト */
double tm0, tm1;
size_t i;
array.resize(n_elements);
/* 乱数の初期化 */
srand48(12345);
/* 配列へ乱数を代入 */
for ( i=0 ; i < array.size() ; i++ ) {
array[i] = drand48();
}
#define USE_STDSORT
/* sort を行ない,経過時間を測る */
#ifdef USE_STDSORT
/* C++ の std::sort() を使う */
tm0 = clock() / (double)CLOCKS_PER_SEC;
std::sort(&array[0], &array[0] + array.size());
tm1 = clock() / (double)CLOCKS_PER_SEC;
printf("time: %g\n",tm1 - tm0);
#else
/* LIBC の qsort() を使う */
tm0 = clock() / (double)CLOCKS_PER_SEC;
qsort(&array[0], array.size(), sizeof(array[0]), &compar_float);
tm1 = clock() / (double)CLOCKS_PER_SEC;
printf("time: %g\n",tm1 - tm0);
#endif
/* 配列の内容を10個表示 */
for ( i=0 ; i < 10 ; i++ ) {
printf("[%g]",array[i]);
}
printf("\n");
return 0;
}
○実習7○
上記のコードの動作確認を行ない,
qsort(), std::sort() それぞれの性能を
確認してください.
発展学習:
本来は,std::vector のオブジェクトを
std::sort() に与える時は,
std::sort(array.begin(), array.end());
とします.この array.begin(),
array.end() が返す型は
「イテレータ」という特殊な型で,機能強化版のポインタ型のようなものです.
C++標準ライブラリのテンプレートクラスでは,このイテレータにより,
オブジェクト内で管理されるデータがどんなデータ構造であっても,
同じ記法で1つ1つのデータ要素にアクセスできるようになっています.
C++ 標準ライブラリを使ってみて, C言語の欠点を補っている事が理解できたと思います. しかし,科学研究で多用される多次元配列を扱うためのクラスはありませんし, 文字列の扱いなどをみても日常的に必要な API が揃っておらず, スクリプト言語に比べると実用面では見劣りする部分があります.
SLLIB (えすえるりぶ) は,そのような問題を解決するために, 研究者の視点で開発された,新しい C++ の基本ライブラリです. 「1.ストリーム」 「2.文字列」 「3.多次元配列」 の『3点セット』について,スクリプト言語のような API を C++ 環境で使えるよう にし,科学研究に適した 【実用的な言語環境】を提供します.
次のような特徴を持ちます:
ここからは,いよいよ SLLIB を使ってコードを作りますので, 講習はかなり「簡単」になっていきます. ここまでみなさんよく我慢したと思います.
SLLIB をインストールすると,「s++」という
コマンド(シェルスクリプト)が使えるようになります.
s++ は g++ に対する
wrapper で,SLLIB や SFITSIO を使う時は,
これを使ってコンパイルすると,最小の引数で済み,手間いらずです.
では早速,s++ コマンドを使ってみましょう.
$ s++ [USAGE] - To compile: $ s++ main.cc sub1.cc sub2.cc ... - To compile/run: $ s++ main.cc sub1.cc sub2.cc ... / arg1 arg2 ... - To create a new template of source file: $ s++ foo.cc [HEADER FILES] ==== In /usr/local/include/sli ==== asarray.h httpstreamio.h mdarray_statistics.h asarray_tstring.h inetstreamio.h mdarray_uchar.h bzstreamio.h ldsrpc.h mdarray_uintptr.h complex.h mdarray.h numeric_indefs.h complex_defs.h mdarray_bool.h numeric_minmax.h cstreamio.h mdarray_complex.h pipestreamio.h ctindex.h mdarray_dcomplex.h size_types.h digeststreamio.h mdarray_double.h sli_config.h fits.h mdarray_fcomplex.h sli_eof.h fits_hdu.h mdarray_float.h sli_funcs.h fits_header.h mdarray_int.h sli_seek.h fits_header_record.h mdarray_int16.h slierr.h fits_image.h mdarray_int32.h stdstreamio.h fits_image_statistics.h mdarray_int64.h tarray.h fits_table.h mdarray_llong.h tarray_tstring.h fits_table_col.h mdarray_long.h termlineio.h fitscc.h mdarray_math.h termscreenio.h ftpstreamio.h mdarray_short.h tregex.h gzstreamio.h mdarray_size.h tstring.h heap_mem.h mdarray_ssize.h xmlparser.h [EXAMPLE FILES] ==== In /usr/local/share/doc/sllib/examples ==== array_basic.cc gnuplot_animation.cc string_array_basic.cc array_digest.cc http_client.cc string_basic.cc array_edit.cc read_local_text_file.cc string_bracket.cc array_fast_access.cc read_text_from_net.cc string_edit.cc array_idl.cc readline.cc string_match.cc array_math.cc regexp_back_reference.cc string_regexp.cc array_statistics.cc split_string.cc verbose_grep.cc associative_string_array.cc stdout_stderr.cc ==== In /usr/local/share/doc/sfitsio/examples ==== combine_fits_images.cc create_fits_vl_array.cc combine_fits_images_md.cc dump_fits_table.cc create_fits_asciitable.cc read_and_write_fits.cc create_fits_bintable.cc read_fits_header.cc create_fits_image.cc stat_fits_image_pixels.cc create_fits_image_and_header.cc stat_fits_image_pixels_md.cc ==== In /usr/local/share/doc/sfitsio/tools ==== conv_fits_image_bitpix.cc fits_dataunit_md5.cc transpose_fits_image.cc create_fits_from_template.cc hv.cc fill_fits_header_comments.cc rotate_fits_image.cc
s++ を引数なしで使うと,
s++コマンドの使い方,
SLLIBのヘッダファイル一覧と置き場所,
サンプルコードのファイル一覧と置き場所が表示されます.
サンプルコードはファイルをコピーして使っても良いですし,
この後の方法でコードのテンプレートとして
カレントディレクトリにコピーする事もできます.
○実習8○
次の手順で最も基本的なコードのテンプレートを作り, コードを確認し,コンパイル,実行してみてください.
$ s++ sllib_sample.ccと入力すると,どのテーマからコードを生成するか聞かれるので「0」を指定.
$ less sllib_sample.cc
$ s++ sllib_sample.cc $ ./sllib_sampleこの時,「
-Wall -O -o ...」のような引数は不要です.
自動的にセットされます.
$ s++ sllib_sample.cc /とすると,コンパイル直後にプログラムを実行します. 「
/」の後にプログラムに対する引数を与える事もできます.
SLLIBのストリーム に関するインタフェースは, C標準(C++標準ではない)とほとんど同じです. それでいて,様々なストリーム (gzip圧縮,bzip2圧縮,ftp,http等) に柔軟に対応できるようになっています.
次の表は, SLLIBのストリーム に関する概略です. ストリームを扱うための様々なクラスがあり, クラスによって扱えるストリームの種類が異なります. 注目してもらいたいのは,どのクラスにおいても 基本的な処理のためのメンバ関数は全く同じだという事です. したがって,基本的には1つのクラスの使い方を覚えるだけで, 他のクラスも追加学習なしで使えてしまうわけです.
上の表のうち,上半分が各クラスに共通しているメンバ関数で, これらは基底クラス cstreamio で規定しています. cstreamio クラスはプログラマは直接使う事はできません (このようなものを抽象基底クラスといいます).
| 抽象基底クラス | ストリームの種類・機能 |
|---|---|
| cstreamio | 基本的なメンバ関数の仕様を定義しているクラス |
下記がプログラマが使う事のできるクラスで,cstreamioを継承しています (このようなものを継承クラスといいます).
| 継承クラス | include | ストリームの種類・機能 |
|---|---|---|
| stdstreamio | #include <sli/stdstreamio.h> |
標準入出力・標準エラー出力・標準ファイル入出力
(stdio.hに相当) |
| gzstreamio | #include <sli/gzstreamio.h> |
gzip圧縮・伸長に対応したファイル入出力 |
| bzstreamio | #include <sli/bzstreamio.h> |
bzip2圧縮・伸長に対応したファイル入出力 |
| httpstreamio | #include <sli/httpstreamio.h> |
httpサーバからの入力(download) |
| ftpstreamio | #include <sli/ftpstreamio.h> |
ftpサーバから入力(download)・ftpサーバへ出力(upload) |
| pipestreamio | #include <sli/pipestreamio.h> |
パイプから入力・パイプへの出力 |
| digeststreamio | #include <sli/digeststreamio.h> |
万能なストリーム用クラス.{std, gz, bz, http, ftp}streamioをパス名によって自動的に切り替えて利用 |
| termlineio | #include <sli/termlineio.h> |
便利なコマンド入力(GNU readlineへのwrapper) |
| termscreenio | #include <sli/termscreenio.h> |
端末スクリーンへの入力・出力(ページャ・エディタを起動) |
| inetstreamio | #include <sli/inetstreamio.h> |
シーケンシャル・1or2ウェイ接続用の低レベルインターネットクライアント |
実習8 で作られたコードのテンプレートは次のようなものでした.
#include <sli/stdstreamio.h>
using namespace sli;
/*
* Basic examples for STDOUT and STDERR
*/
int main( int argc, char *argv[] )
{
stdstreamio sio; /* object for stdin, stdout */
sio.printf("This is stdout\n"); /* to stdout */
sio.eprintf("This is stderr\n"); /* to stderr */
return 0;
}
SLLIB を使う場合,ストリームはこのように必ずオブジェクト(インスタンス)を
作ってからメンバ関数を呼び出す形をとります.
オブジェクト「sio」は初期状態では標準入出力につながっており,
open() メンバ関数などでファイルを開くと,
そちらへ接続します.
もちろん,「sio.printf()」「sio.eprintf()」
ではなく,
今まで通りに「printf()」「fprintf(stderr,...)」
を使ってもかまいません.
では,今度はファイルをオープンしてみましょう.
○実習9○
sllib_read_text.cc),
コンパイルして,テキストファイル(例えば /usr/include/stdio.h)
を第1引数として動作を確認してください.
#include <sli/stdstreamio.h>
using namespace sli;
int main( int argc, char *argv[] )
{
int ret_status = -1;
stdstreamio sio; /* stdin, stdout and stderr */
stdstreamio f_in; /* for local file */
if ( 1 < argc ) {
const char *filename = argv[1];
const char *line; /* for a line */
/* ストリームをオープン */
if ( f_in.open("r", filename) < 0 ) {
sio.eprintf("[ERROR] cannot open: %s\n",filename);
goto quit;
}
/* テキストファイルを 1 行ずつ読む */
while ( (line=f_in.getline()) != NULL ) {
sio.printf("%s",line);
}
/* ストリームをクローズ */
f_in.close();
}
ret_status = 0;
quit:
return ret_status;
}
$ ./sllib_read_text https://www.adc.nao.ac.jp/
#include <sli/digeststreamio.h>「
stdstreamio f_in;」を
digeststreamio f_in;
に書き換え,コンパイルしてください.
$ ./sllib_read_text https://www.adc.nao.ac.jp/
$ cp /usr/include/stdio.h . $ gzip stdio.h $ ./sllib_read_text stdio.h.gz
open() メンバ関数は,
LIBC では fopen() 関数に相当するものです.
オープンが失敗すると負の値を返します.
なお,引数の順序が fopen() の場合とは
逆になっている点に注意してください.
この理由は,
openf() というメンバ関数も存在し,
その場合は次にように printf() と同じ可変引数が使えるようになっており,
メンバ関数の整合性を保つためなのです.
/* 連続した数字がついたファイルを順に開く */
for ( i=0 ; i < N ; i++ ) {
f_in.openf("r", "ftp://foo.ac.jp/file_%d.txt.gz", i);
:
f_in.close();
}
getline() メンバ関数は,
オブジェクト内部にバッファを用意し,テキストファイルを1行分読み取って
バッファに保存し,そのアドレスを返します(1行の長さに関する制限はありません).
EOF に達した場合は NULL を返します.
内部バッファはライブラリで自動管理されているので,
プログラマが開放してはいけません.
なお,
SLLIBのストリーム
を扱うクラスでは,
ストリームのクローズも自動です.
もちろん,close() メンバ関数を使ってクローズした方が
良いですが,書き忘れた場合でもスコープを抜けると
ライブラリ側でクローズ処理が行なわれます.
自分で計算したデータを gnuplot でプロットしたい場合, 普通はデータをファイルに落としてから gnuplot の plot コマンドを使います.
pipestreamio クラスと FIFO とを使うと, コマンドをパイプ経由で送信し, データをファイルに落とさず高速に gnuplot へ送信する事ができます.
FIFO の作り方は簡単で,
$ mkfifo fifo0 fifo1
のようにするだけです.これで fifo0,fifo1
という FIFO のための特別なファイルができました.
例えばプロセスA が通常のファイルと同様に fifo0 に書き込み,
プロセスB が通常のファイルと同様に fifo0 から読み込むと,
データはプロセスA からプロセスB に伝わるようになります.
試しに FIFO をターミナルから使ってみましょう. まず,1つのターミナルで
$ cat fifo0
としてください.その後,別のナーミナルを開き,fifo0
に対して書き込みます:
$ echo "Hello" > fifo0
すると,最初のターミナルに「Hello」と表示されます.
この動作をうまく使うと,
データをファイルに書き出さずにプロセス間の通信で
プロットツールでのグラフ描画が可能になります.
次のコードは,プログラム側で sin() と cos() の関数の値を計算し, gnuplot に FIFO でデータを与えて描画させるためのコードです. 極めて平凡なコードである事がおわかりいただけると思います.
#include <math.h>
#include <sli/stdstreamio.h>
#include <sli/pipestreamio.h>
using namespace sli;
int main( int argc, char *argv[] )
{
int ret_status = -1;
pipestreamio p_out;
stdstreamio sio, f_out;
int i;
/* gnuplot を起動 */
if ( p_out.open("w", "gnuplot") < 0 ) {
sio.eprintf("[ERROR] p_out.open() failed\n");
goto quit;
}
/* gnuplot へコマンドを送信 */
p_out.printf("plot \"fifo0\" with lines, \"fifo1\" with lines\n");
p_out.flush();
/* fifo0 経由で gnuplot へデータを送信 */
if ( f_out.open("w","fifo0") < 0 ) {
sio.eprintf("[ERROR] f_out.open() failed\n");
goto quit;
}
for ( i=0 ; i < 1000 ; i++ ) {
double x = 4 * M_PI * i / 1000.0;
f_out.printf("%.15g %.15g\n", x, sin(x));
}
f_out.close();
/* fifo1 経由で gnuplot へデータを送信 */
if ( f_out.open("w","fifo1") < 0 ) {
sio.eprintf("[ERROR] f_out.open() failed\n");
goto quit;
}
for ( i=0 ; i < 1000 ; i++ ) {
double x = 4 * M_PI * i / 1000.0;
f_out.printf("%.15g %.15g\n", x, cos(x));
}
f_out.close();
/* ターミナルから入力を待つ */
sio.getchr();
/* gnuplot への接続をクローズ */
p_out.close();
ret_status = 0;
quit:
return ret_status;
}
注意点は,FIFO に書き込む順番は, gnuplot の plot コマンドに与えた FIFO の順に一致させる事です.
○実習10○
参考:
SLLIB ダイジェスト版 リファレンス 「ストリーム」
SLLIB では文字列を扱うのに 「tstring」 というクラスを使います. tstringクラス はスクリプト言語のように文字列を扱えるようにするもので, オブジェクトの内部に自動管理されるヒープバッファを持ち,そこに 文字列が記録されます. バッファの大きさの変更,バッファの開放は自動的に行なわれ, 高い安全性を持ちます.
早速コードを見ていきましょう.
#include <sli/stdstreamio.h>
#include <sli/tstring.h>
using namespace sli;
int main( int argc, char *argv[] )
{
stdstreamio sio;
tstring my_str; /* 文字列オブジェクトを作る */
my_str = "Hello World"; /* "Hello World" を my_str に代入 */
sio.printf("my_str = '%s'\n", my_str.cstr());
return 0;
}
C言語で,
const char *my_str = "Hello World";
とすると,文字列定数 "Hello World" の先頭アドレスが
my_str に記録されましたが,
tstring
の場合は,文字列定数 "Hello World" の文字列が
オブジェクト内部のバッファにコピーされます.
そして,printf() の %s などで
文字列の先頭アドレスが必要な場合は,
.cstr()
で内部バッファのアドレスを取得します.
これだけのコードだと 一見面倒なように見えますが,文字列の変更のような事をしようとすると, C言語の時よりずっと簡単かつ安全に目的の処理を行なう事ができます.
○実習11○
my_str[13] = '!';
my_str[14] = '!';
sio.printf("my_str = '%s'\n", my_str.cstr());
実習11 では,
[i]
でアクセスした場合も,
内部バッファの大きさは自動的に調整される事が理解できたと思います.
tstring クラスは,バッファの自動化だけでなく, 様々な文字列編集のためのメンバ関数が揃っている事も特徴の1つです. 文字列の追加,文字列の左右の空白の除去,小文字への変換を行なってみましょう.
#include <sli/stdstreamio.h>
#include <sli/tstring.h>
using namespace sli;
int main( int argc, char *argv[] )
{
stdstreamio sio;
tstring my_str; /* 文字列オブジェクトを作る */
my_str = " Hello "; /* " Hello " を代入 */
my_str.append("WORLD "); /* "WORLD " を追加 */
sio.printf("before: '%s'\n", my_str.cstr());
my_str.trim(); /* 左右の空白を除去 */
sio.printf("after trim(): '%s'\n", my_str.cstr());
my_str.tolower(); /* 小文字へ変換 */
sio.printf("after tolower(): '%s'\n", my_str.cstr());
return 0;
}
○実習12○
上記のコードの動作確認を行なってください.
単純な文字列比較,シェル風のマッチ,POSIX 拡張正規表現を使って, オブジェクト内文字列の検索,置換が可能です.
次の例は,URL 文字列からホスト名を取り出すのに,
正規表現を使ったものです.
regreplace()
メンバ関数は,拡張正規表現(第1引数)によるマッチを行ない,マッチした部分を
任意の文字列(第2引数)に置き換えるメンバ関数です.
次のように,sed コマンドと同様,「\\1」「\\2」等で
後方参照が使えます.
stdstreamio sio;
tstring my_url = "http://darts.isas.jaxa.jp/foo/";
my_url.regreplace("([a-z]+://)([^/]+)(.*)", "\\2", false);
sio.printf("hostname = %s\n", my_url.cstr());
ストリームのところで登場した getline() メンバ関数と tstring クラスとを組み合わせると, 次のようにスクリプト言語に近い形で, テキストファイルの読み出しを行なう事ができます.
#include <sli/stdstreamio.h>
#include <sli/digeststreamio.h>
#include <sli/tstring.h>
using namespace sli;
/*
* An example code for reading a text file from network
*/
int main( int argc, char *argv[] )
{
int ret_status = -1;
stdstreamio sio; /* stdin, stdout and stderr */
digeststreamio f_in; /* for local file */
if ( 1 < argc ) {
const char *filename = argv[1];
tstring line; /* buffer for a line */
/* ストリームをオープン */
if ( f_in.open("r", filename) < 0 ) {
sio.eprintf("[ERROR] cannot open: %s\n",filename);
goto quit;
}
/* テキストファイルを 1 行ずつ読む */
while ( (line=f_in.getline()) != NULL ) {
line.chomp(); /* erase "\n" */
sio.printf("%s\n",line.cstr());
}
/* ストリームをクローズ */
f_in.close();
}
ret_status = 0;
quit:
return ret_status;
}
chomp()
は,文字列の右端の改行文字を除去するためのメンバ関数です.
上記のコードの while() の部分は,SLLIB で良く使う
コードのパターンですので,覚えておくと便利です.
参考:
SLLIB ダイジェスト版 リファレンス 「文字列」
SLLIB で文字列配列を扱うには, tarray_tstringクラス を使います. このクラスも tstring クラスと同様, ほぼ完全なメモリの自動管理により,易しく安全に文字列配列を扱う事ができま す.C言語のポインタ配列との親和性も考慮した設計と API により, 様々な場面で応用できるのも特徴の1つです.
tstring では,
あらかじめバッファを確保していなくても [i] で
いきなり代入できました.これは,tarray_tstring でも同じです.
例を示します.
#include <sli/stdstreamio.h>
#include <sli/tarray_tstring.h>
using namespace sli;
int main( int argc, char *argv[] )
{
tarray_tstring my_arr;
my_arr[2] = "fuji";
my_arr[3] = "hayabusa";
my_arr.dprint();
return 0;
}
このコードの最後の
dprint()
は,
オブジェクトの内容を標準エラー出力に出力するものです.
次のような表示を得ます.
sli::tarray_tstring[obj=0xbfffee08] = {"", "", "fuji", "hayabusa"}
これにより,いちいち for ループを書かなくても, 内容の確認を手早く行なう事ができます. もちろん,for ループで1つ1つ内容を表示する事もできて, その場合は,次のように書きます.
stdstreamio sio;
size_t i;
for ( i=0 ; i < my_arr.length() ; i++ ) {
sio.printf("my_arr[%zu] = '%s'\n", i, my_arr[i].cstr());
}
length() で配列の個数,
[i]
で tstring オブジェクトの参照を取得します.
注意していただきたいのは,[i] の後についている
.cstr() は
tstring クラスのメンバ関数
であるという事です.これはつまり,
tarray_tstring オブジェクトは,
その内部に配列要素の個数分のtstringオブジェクトを持っていて,
[i] で該当する内部の tstring オブジェクトを
引き出している,という事になります.
このように,オブジェクトの内部で,別のクラスの複数のオブジェクトを管理している,
という手法はオブジェクト指向の基本的なパターンであり,
今後もずっと出てきますので,注意してみていてください.
内部のオブジェクトを引き出すメンバ関数の形としては,
[i] や .at(i) が多いですが,
より具体的な名前である事もあります.
○実習13○
const char *line = " Z-80,, 8086 , 6800";
tarray_tstring my_arr;
my_arr.split(line, ",", true);
my_arr.dprint();
動作確認を行なってください.
my_arr.split(line, " ", false);
のように書くと,
空白区切りに対応します.動作確認を行なってください.
my_arr.trim();
my_arr.dprint();
文字列のポインタ配列の情報を,まるごと配列にぶちこむのも
= 記号
一発です.
#include <sli/tarray_tstring.h>
using namespace sli;
int main( int argc, char *argv[] )
{
tarray_tstring args;
args = argv;
args.dprint();
return 0;
}
ここから正規表現などを使って引数をチェックしたり, 値の変換をしたり,チェック済みの引数を削除したり, 様々な応用が安全かつ簡単に行なえます.
正規表現の (…) により,
文字列をいくつかのパーツへ分割したい事があります.
このような場合は,
regassign()
メンバ関数を使うと,
マッチした部分の情報を tarray_tstring の文字列配列として取得する事ができます.
例を示します.
stdstreamio sio;
tarray_tstring my_elms;
tstring my_str = "OS = linux";
my_elms.regassign(my_str, "([^ ]+)([ ]*=[ ]*)([^ ]+)");
if ( my_elms.length() == 4 ) {
sio.printf("keyword=[%s] value=[%s]\n",
my_elms[1].cstr(), my_elms[3].cstr());
}
これを実行すると,次の結果を得ます.
keyword=[OS] value=[linux]
このように正規表現の (…) が3つのパートを指定し,それが
マッチした場合は,文字列配列の長さが 4 になります.
配列の各内容については,
my_elms[0] にマッチした全体の部分,
my_elms[1] に1つめの (…) 部分,
my_elms[2] に2つめの (…) 部分,のように
セットされます.
次のような高度な文字列分割も行なえます.空白区切りの文字列を 分割しますが, 括弧内の空白と,クォーテーション内の空白は区切り文字とはみなしません.
const char *line = "winnt( ) 'program files'";
tarray_tstring my_arr;
my_arr.split(line, " ", false, "'()", '\\', false);
my_arr.dprint();
次のような結果を得ます.
sli::tarray_tstring[obj=0xbfffee28] = {"winnt( )", "'program files'"}
◎課題3◎
ここまでくると,もうほとんどスクリプト言語と変わらなくなってきます. 文字列連想配列のためのクラスは asarray_tstring で, さきほどの文字列配列と同じように使えます.
#include <sli/stdstreamio.h>
#include <sli/asarray_tstring.h>
using namespace sli;
int main( int argc, char *argv[] )
{
stdstreamio sio;
asarray_tstring my_arr; /* 文字列の連想配列 */
size_t i;
/* 代入 */
my_arr["JR-EAST"] = "SUICA";
my_arr["JR-CENTRAL"] = "TOICA";
my_arr["JR-WEST"] = "ICOCA";
/* 表示 (もちろん .dprint() を使っても良い) */
for ( i=0 ; i < my_arr.length() ; i++ ) {
const char *key = my_arr.key(i);
sio.printf("%s: [%s]\n", key, my_arr[key].cstr());
}
return 0;
}
文字列配列の場合と同様,内部で複数の tstring のオブジェクトを
管理しており,my_arr[キー文字列] の形で
該当する tstring のオブジェクトを引き出します.簡単ですね.
○実習14○
SLLIB で提供される『3点セット』--- 「1.ストリーム」 「2.文字列」 「3.多次元配列」 のうち, 多次元配列は,科学研究においては特に高い需要があります. にもかかわらず,C++ の世界には多次元配列を扱うのに適当なクラスは あまり見かけません.したがって, SLLIB の最大の強みは,この多次元配列にあり,と言えるでしょう.
SLLIB で多次元配列を扱うためのクラスは mdarray とその継承クラス であり, n次元の配列を最新のスクリプト言語と同様の感覚で扱う事ができます. メモリ管理の自動化はもちろん, mdarray オブジェクトの内部は常に単純な1次元バッファとなっている上, 内部バッファへの直接アクセスを前提とした安全設計により, 従来の C言語のライブラリとのリンクも容易です. 当然,配列の要素の数え方は他のクラスと同様 0-indexed です.
多次元配列のクラスの使い方はストリームの場合と似ており, 「基底クラス」「継承クラス」があります. 基底クラスは「mdarray」で, 継承クラスは「mdarray_double」「mdarray_float」のように 配列で扱う型の名称がつきます.また, 基底クラスは「抽象」ではないので,プログラマが使う事ができます.
| 基底クラス | 説明 |
|---|---|
| mdarray | 型も配列長も可変で,ライブラリの実装などに向いている. 型に依存したメンバ関数が使えないので,配列の1要素ずつのアクセスには向かない. |
通常,プログラマは次に示す継承クラスを使います. 型が固定である事以外のデメリットはなく,異なる型どうしでも, 四則演算を含む様々な演算が可能です.
| 継承クラス | 説明 | 演算子による演算 |
|---|---|---|
| mdarray_double | double 型を扱う | Yes |
| mdarray_float | float 型を扱う | Yes |
| mdarray_uchar | unsigned char 型を扱う | Yes |
| mdarray_short | short 型を扱う | Yes |
| mdarray_int | int 型を扱う | Yes |
| mdarray_long | long 型を扱う | Yes |
| mdarray_llong | long long 型を扱う | Yes |
| mdarray_int16 | int16_t 型を扱う | Yes |
| mdarray_int32 | int32_t 型を扱う | Yes |
| mdarray_int64 | int64_t 型を扱う | Yes |
| mdarray_bool | bool 型を扱う | - |
| mdarray_size | size_t 型を扱う | - |
| mdarray_ssize | ssize_t 型を扱う | Yes |
| mdarray_uintptr | uintptr_t型を扱う | - |
| mdarray_fcomplex | sli::fcomplex 型を扱う | Yes |
| mdarray_dcomplex | sli::dcomplex 型を扱う | Yes |
配列データを「継承クラス」「基底クラス」の間で移動させる事ができるので, 必要になった時点でクラスを切り替える事も容易です.
mdarray とその継承クラスには,2つの動作モード
「自動リサイズモード」「手動リサイズモード」があります.
前者はこれまで見てきた文字列配列のように,[i] のような
要素へのアクセスで自動的にバッファを再確保するモードです.
後者は std::vector のようにバッファの自動確保をせず
resize() メンバ関数など
を使ってプログラマがバッファの大きさを設定するモードです.
どちらも,スコープを抜けた時のメモリの自動開放と,
[i] のようなアクセスでの
バッファ境界のチェックが入るなどの安全性は文字列配列などの場合と同じです.
観測データの場合は,2次元以上のデータが多く,バッファの大きさは 頻繁にリサイズしないと思いますので, 基本的には「手動リサイズモード」を使う方向で良いと思います.
次に,基本的なコードの例を示します.
#include <sli/mdarray.h> /* mdarrayクラスとその継承クラス */
#include <sli/mdarray_statistics.h> /* 統計用の関数 */
#include <sli/mdarray_math.h> /* 配列に対する数学関数 */
using namespace sli;
int main( int argc, char *argv[] )
{
/* オブジェクトを作成 */
/* 引数は assign() 等での自動リサイズ on/off を設定 */
mdarray_float arr0(false);
/* 配列の大きさを設定し,値を代入 */
arr0.resize_2d(8,4);
arr0 = 500.0;
arr0 *= 2;
arr0.dprint();
return 0;
}
まず,ヘッダファイルは sli/mdarray.h を include すれば
すべての継承クラスが使用できるようになります.
オブジェクト arr0 を作るところで,
引数を与えていますが,これが動作モードを決めます.この例では,
手動リサイズモードを選択しています.その後,
resize_2d()
で 8 × 4 の2次元配列とし,
全配列要素に対してスカラー値 500.0 を代入,スカラー値 2 を掛けています.
これを実行すると次のような結果を得ます.
sli::mdarray[obj=0xbffff4e0, sz_type=-4, dim=(8,4)] = {
{ 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000 },
{ 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000 },
{ 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000 },
{ 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000 }
}
○実習15○
上記のコードの動作確認を行なってください.
3つの方法を示します. まずは,安全な方法です.
size_t i, j;
for ( i=0 ; i < arr0.row_length() ; i++ ) { /* Y */
for ( j=0 ; j < arr0.col_length() ; j++ ) { /* X */
arr0(j,i) = 100 + 10*i + j;
}
}
arr0.dprint();
[] ではなく,丸括弧で
arr0(x,y)
のようにアクセスします.
この方法では常にバッファ境界のチェックが入り,
範囲外に書き込んでも単に無視されます
(範囲外を読み込んだ場合は NAN が返ります).
次に示す方法に比べて性能は劣りますが,
スクリプト言語に比べれば十分高速です.
第3部では,この丸括弧で要素にアクセスする方法を使っています.
次は高速な方法です.
float *const *arr0_ptr = arr0.array_ptr_2d(true);
size_t i, j;
for ( i=0 ; i < arr0.row_length() ; i++ ) { /* Y */
for ( j=0 ; j < arr0.col_length() ; j++ ) { /* X */
arr0_ptr[i][j] = 100 + 10*i + j;
}
}
arr0.dprint();
arr0.array_ptr_2d(true)
とすると,2次元データにアクセスするためのポインタ配列を
オブジェクト内部で生成してくれるので,それを使います.
こうする事で,
arr0_ptr[y][x]
の形で各要素に高速にアクセスする事ができます.
このポインタ配列はリサイズ等が行なわれると,自動的に更新されるように
なっています.
3次元データ用の array_ptr_3d() もあります.
オブジェクト内部の配列データは常に1次元バッファで管理されていますから, 内部バッファのアドレスを 単純なポインタ変数に取得して,要素にアクセスする事もできます.
float *arr0_ptr = arr0.array_ptr();
size_t i, j, ii;
ii = 0;
for ( i=0 ; i < arr0.row_length() ; i++ ) { /* Y */
for ( j=0 ; j < arr0.col_length() ; j++ ) { /* X */
arr0_ptr[ii] = 100 + 10*i + j;
ii ++;
}
}
arr0.dprint();
当然ですが,ポインタ変数で要素にアクセスする場合は バッファの境界チェックは一切行なわれません.
○実習16○
上記の3つのコードで,配列の要素にどれも同じ値が入る事を 確認してください.
上で作った float 型の2次元配列 arr0 の一部を切り出し,
double 型の配列オブジェクトへコピーしてみましょう.
mdarray_double arr1(false);
arr1 = arr0.sectionf("1:4, *");
arr1.dprint();
「"1:4, *"」が IDL 的な表記で,
「横方向は 1〜4 までの要素,縦方向はすべての要素」を示しています.
もちろん,要素の番号は 0-indexed です.
なお,FITSファイルのヘッダなどに,IRAF的表記で 1-indexed で配列の範囲が
書かれている事もあります.その場合は,"[…,…]" のように
書けば 1-indexed として扱われます.
今の場合は,"[2:5, *]" と書く事もできるわけです.
○実習17○
実習16のコードのつづきに上記のコードを追加し, 次のような値になる事を確認してください.
sli::mdarray[obj=0xbffff2c0, sz_type=-8, dim=(4,4)] = {
{ 101, 102, 103, 104 },
{ 111, 112, 113, 114 },
{ 121, 122, 123, 124 },
{ 131, 132, 133, 134 }
}
上で作った arr1 の要素を
arr0 に貼り付けてみましょう.
arr0.pastef(arr1, "*, 2:3");
arr0.dprint();
pastef()
の2つ目の引数で,arr0 のどの部分に
貼り付けるのかを指定します.
結果は次のとおり.左下の 4 × 2 の部分が貼り付けた部分です.
sli::mdarray[obj=0xbffff4e0, sz_type=-4, dim=(8,4)] = {
{ 100, 101, 102, 103, 104, 105, 106, 107 },
{ 110, 111, 112, 113, 114, 115, 116, 117 },
{ 101, 102, 103, 104, 124, 125, 126, 127 },
{ 111, 112, 113, 114, 134, 135, 136, 137 }
}
では,この状態からさらに同じ部分を arr1 で
割ってみましょう.
arr0.dividef(arr1, "*, 2:3");
arr0.dprint();
○実習18○
実習17のコードのつづきに上記のコード(ペーストおよび割り算)を追加し, 次のような値になる事を確認してください.
sli::mdarray[obj=0xbffff4e0, sz_type=-4, dim=(8,4)] = {
{ 100, 101, 102, 103, 104, 105, 106, 107 },
{ 110, 111, 112, 113, 114, 115, 116, 117 },
{ 1, 1, 1, 1, 124, 125, 126, 127 },
{ 1, 1, 1, 1, 134, 135, 136, 137 }
}
sli/mdarray_math.h を include すると,
mdarray クラスやその継承クラスの配列オブジェクトに対し,
数学関数を使う事ができます.
math.h で定義されているほとんどの数学関数をサポートしています.
例えば,配列の全要素を 2乗する場合は,次のように書く事ができます.
arr0 = pow(arr0, 2.0);
arr0.dprint();
結果は次のようになります.
sli::mdarray[obj=0xbffff4e0, sz_type=-4, dim=(8,4)] = {
{ 10000, 10201, 10404, 10609, 10816, 11025, 11236, 11449 },
{ 12100, 12321, 12544, 12769, 12996, 13225, 13456, 13689 },
{ 1, 1, 1, 1, 15376, 15625, 15876, 16129 },
{ 1, 1, 1, 1, 17956, 18225, 18496, 18769 }
}
sli/mdarray_statistics.h を include すると,
mdarray クラスやその継承クラスの配列オブジェクトに対しする
統計用の関数
を使う事ができます.
すべての関数のコードは,
sli/mdarray_statistics.h に記述されているため,
SLLIB がインストールされている環境ならコードの確認・流用が手軽に行なえます.内容を確認してみましょう.
$ less /usr/local/include/sli/mdarray_statistics.h
arr0 の代表的な統計量を計算してみましょう:
/* get mean, variance, skewness, kurtosis */
mdarray_double moment = md_moment(arr0, false, NULL, NULL);
moment.dprint();
平均,分散,歪度,尖度を得ました.
sli::mdarray[obj=0xbfffee80, sz_type=-8, dim=(4)] = {
10165.625, 41496969.79, -0.6201298573, -1.038419883
}
x方向,y方向あるいは z方向に統計をとり, 元の配列から次元数を1次元減らし,統計値を要素にセットした配列 を取得する事ができます.
例えば,これまでのコードの続きで arr0
を y 方向に median をとる場合は次のように書きます.
arr1 = md_median_y(arr0);
arr1.dprint();
次のような結果を得ます.
sli::mdarray[obj=0xbffff2c0, sz_type=-8, dim=(8,1)] = {
{ 5000.5, 5101, 5202.5, 5305, 14186, 14425, 14666, 14909 }
}
○実習19○
数学関数,統計値について示したコードの動作確認を行なってください.
SLLIB のメンバ関数や関数には,特別な最適化がなされているものもあります. そのパフォーマンスを確認してみましょう.
第一部の 「ハードウェアを意識しよう: メモリアクセス」 では,巨大二次元配列の x と y との入れ換えを行なう場合, 単純な方法ではパフォーマンスが出ない事を説明しました. SLLIB はこのトランスポーズを行なうための最適化されたコードを持っていますので, 試してみましょう.
以下のコードは,2次元配列 arr0 から,
トランスポーズされた2次元配列 arr1 を作るものですが,
次の2つの場合について実行速度を測るものです.
transpose_xy_copy() を使った場合
#include <sli/stdstreamio.h>
#include <sli/mdarray.h>
#include <stdlib.h>
#include <time.h>
using namespace sli;
const size_t Width = 4096*1;
const size_t Height = 4096*1;
int main( int argc, char *argv[] )
{
stdstreamio sio;
mdarray_double arr0, arr1;
double tm0, tm1;
size_t i;
arr0.resize_2d(Width,Height);
arr1.resize_2d(Width,Height);
double *const *arr0_ptr2d = arr0.array_ptr_2d(true);
double *const *arr1_ptr2d = arr1.array_ptr_2d(true);
/* set random number */
srand48(12345);
for ( i=0 ; i < arr0.row_length() ; i++ ) { /* Y */
size_t j;
for ( j=0 ; j < arr0.col_length() ; j++ ) { /* X */
arr0_ptr2d[i][j] = drand48();
}
}
/* transpose: arr0 => arr1 */
if ( arr0.col_length() == arr1.row_length() &&
arr0.row_length() == arr1.col_length() ) {
#define USE_SIMPLE_METHOD 1
#ifdef USE_SIMPLE_METHOD
const size_t len_sq = arr0.col_length();
tm0 = clock() / (double)CLOCKS_PER_SEC;
for ( i=0 ; i < len_sq ; i++ ) {
size_t j;
for ( j=0 ; j < len_sq ; j++ ) {
arr1_ptr2d[i][j] = arr0_ptr2d[j][i];
}
}
tm1 = clock() / (double)CLOCKS_PER_SEC;
sio.printf("direct 2d ptr transpose: %g\n",tm1 - tm0);
#else
tm0 = clock() / (double)CLOCKS_PER_SEC;
arr0.transpose_xy_copy(&arr1);
tm1 = clock() / (double)CLOCKS_PER_SEC;
sio.printf("transpose_xy_copy(): %g\n",tm1 - tm0);
#endif
}
arr0.dprint();
arr1.dprint();
return 0;
}
○実習20○
上記のコードについて,#define USE_SIMPLE_METHOD 1
を有効にした場合,無効にした場合の動作速度を確認してください.
SLLIB の 多次元配列用の統計用関数 によって計算される median は,IRAF のような近似値ではなく, 本物の median です. これも最適化がなされているので,その速度性能を計ってみましょう.
以下のコードは,次の2つの場合について実行速度を測るものです.
mdarray_statistics.h
の md_median() を使った場合
#include <sli/stdstreamio.h>
#include <sli/mdarray.h>
#include <sli/mdarray_statistics.h>
#include <stdlib.h>
#include <time.h>
#include <algorithm> /* std::sort() を使うために必要 */
using namespace sli;
const size_t Width = 4096*1;
const size_t Height = 4096*1;
int main( int argc, char *argv[] )
{
stdstreamio sio;
mdarray_double arr0;
double tm0, tm1;
size_t i;
arr0.resize_2d(Width,Height);
double *arr0_ptr = arr0.array_ptr();
/* set random number */
srand48(12345);
for ( i=0 ; i < arr0.length() ; i++ ) {
arr0_ptr[i] = drand48();
}
/* get median */
#define USE_STD_SORT 1
#ifdef USE_STD_SORT
tm0 = clock() / (double)CLOCKS_PER_SEC;
std::sort(arr0_ptr, arr0_ptr + arr0.length());
double median = ( arr0[arr0.length() / 2 - 1] +
arr0[arr0.length() / 2] ) / 2.0;
tm1 = clock() / (double)CLOCKS_PER_SEC;
sio.printf("using std::sort(): %g\n",tm1 - tm0);
sio.printf("median = %.15g\n",median);
#else
tm0 = clock() / (double)CLOCKS_PER_SEC;
double median = md_median(arr0);
tm1 = clock() / (double)CLOCKS_PER_SEC;
sio.printf("using md_median(): %g\n",tm1 - tm0);
sio.printf("median = %.15g\n",median);
#endif
return 0;
}
○実習21○
上記のコードについて,#define USE_STD_SORT 1
を有効にした場合,無効にした場合の動作速度を確認してください.
いよいよ FITS ファイルを扱います. FITS ファイルの規約を理解していれば, LIBC あるいは SLLIB の関数を使って自力で I/O を行なう事もできますが, 最近は FITS の規約も複雑化している事もあり, FITS I/O のためのライブラリを使うのが一般的です.

FITS I/O のライブラリは,Python では PyFITS, IDL では AstroLib (MRDFITS),C では CFITSIO,C++ では CCFITS などがあります. ここで扱う SFITSIO は PyFITS や IDL の MRDFITS に近く, オブジェクト指向の「オンメモリ型」の FITS I/O ライブラリです. ディスクベースの FITS I/O のための API も提供しており, ヘッダのみの高速読み取りのような応用が可能です. SLLIB と同様,プログラマが科学の本質部分のコーディングに集中できる 開発環境を提供する事を目的に開発され, JAXA 宇宙科学研究所の基幹部分でも使われています.
右図は SFITSIO を使った場合の典型的なプログラムが, どのような構成になるかを示しています. この図に示すとおり,SFITSIO は SLLIB の上に載っかっているライブラリです. この2つのライブラリは同じような設計思想を持ちますので, SLLIB を使った経験があれば SFITSIO の使用も簡単です.
IRAF の imcopy タスクは,FITS ファイル(画像)の一部を読み取り, 別の FITS ファイルへ保存するものでした.
これと同じようなものを作ってみましょう. なんだか難しいような気がしますが, SFITSIO では「読んで」「書く」, 2つのメンバ関数 を使うだけです.
#include <sli/stdstreamio.h>
#include <sli/fitscc.h> /* SFITSIO 使用時はこれを includeすればOK */
using namespace sli;
int main( int argc, char *argv[] )
{
int return_status = -1;
stdstreamio sio; /* standard I/O */
fitscc fits; /* FITS object */
/* FITSファイルを読み,fits オブジェクトに内容を保持させる */
if ( 1 < argc ) {
const char *in_file = argv[1];
if ( fits.read_stream(in_file) < 0 ) {
sio.eprintf("[ERROR] fits.read_stream(\"%s\") failed\n",in_file);
goto quit;
}
}
/* fits オブジェクトの内容を FITSファイルとして保存する */
if ( 2 < argc ) {
const char *out_file = argv[2];
if ( fits.write_stream(out_file) < 0 ) {
sio.eprintf("[ERROR] fits.write_stream(\"%s\") failed\n",out_file);
goto quit;
}
}
return_status = 0;
quit:
return return_status;
}
上のコードはエラーのチェックが入っているのでやや長くなっていますが, 本質的な部分は
fits.read_stream(argv[1]);
fits.write_stream(argv[2]);
の2行だけです.
SFITSIO を使ったコードをコンパイルする時は,次のように
「-lsfitsio」を最後の引数として追加します.
$ s++ read_and_write.cc -lsfitsio
これで imcopy に相当するものができました.
○実習22○
$ ./read_and_write M83_DSS2_R_A2EE.fits.gz out_0.fits
$ ./read_and_write M83_DSS2_R_A2EE.fits.gz'[0]' out_1.fitsこの場合,続く HDU へはアクセスせず, Primary HDU の読み取りが完了した時点でストリームをクローズします. したがって,続く HDU が破損していた場合や ゴミデータが続くような不正な FITS ファイルでも,
[0]
を指定していれば問題なく読む事ができます.
$ ./read_and_write M83_DSS2_R_A2EE.fits.gz'[1:100,*]' out_2.fits厳密には次のように書く:
$ ./read_and_write M83_DSS2_R_A2EE.fits.gz'[0[1:100,*]]' out_3.fits0-indexed で指定する場合は丸括弧を使う:
$ ./read_and_write M83_DSS2_R_A2EE.fits.gz'[0(0:99,*)]' out_4.fits画像データの領域選択については,次元数の制限はありません. 例えば,
[0[*,*,1]] と指定すれば,
3次元データの最初のレイヤだけを選択する事ができます.
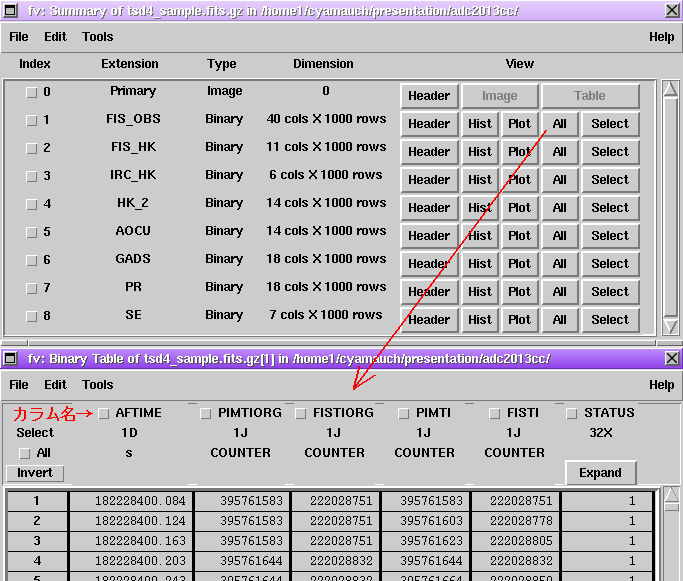
$ ./read_and_write tsd4_sample.fits.gz out_a.fits
$ ./read_and_write tsd4_sample.fits.gz'[0; FIS_HK]' out_b.fits
$ ./read_and_write tsd4_sample.fits.gz'[*{3}]' out_c.fits
$ ./read_and_write tsd4_sample.fits.gz'[*HK*]' out_d.fits
$ ./read_and_write tsd4_sample.fits.gz'[*[*TI*;DET]]' out_e.fits
$ ./read_and_write tsd4_sample.fits.gz'[*[*TI*;DET, 1:100]]' out_f.fits0-indexed で指定する場合は次のとおり.
$ ./read_and_write tsd4_sample.fits.gz'[*(*TI*;DET, 0:99)]' out_g.fits
参考:
ファイル名の後の […] を使った
FITS ファイルの部分読み出し
は,FITS ファイルの内容すべてをメモリに取り込む事はなく,
ディスクのシーケンシャルリードと順方向のシーク(可能な場合)
により実現しています.
したがって,
メモリに載らないような巨大な FITS ファイルでも(圧縮ファイルであっても),
必要な部分を読み出す事ができます.
fitscc fits;
fits.read_stream(in_file);
さきほど出てきたこのコードは,FITS ファイルの内容のすべて
([…] をつけた場合は内容の一部)
を読み取り,fits というオブジェクト(が管理するメモリ)
に取り込むものです.
SLLIB の文字列配列
(tarray_tstringクラス)の扱いでは,
文字列配列オブジェクトの内部で複数の
tstring オブジェクト
が管理されており,それを引き出すのに array[i] のように
した事を思い出してください.
SFITSIO の場合もこれと同様な作りになっていて,
fitsccクラス
のオブジェクトの場合は,
内部で管理しているオブジェクトが入れ子になっていて,
複数のメンバ関数を使って必要な内部オブジェクトを引き出します.
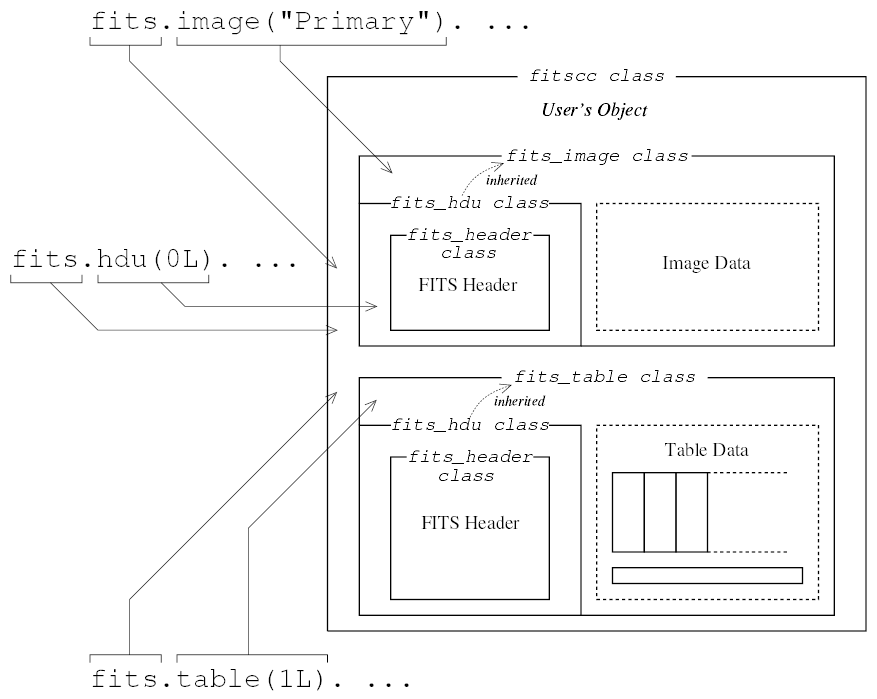
次の図は,fitscc オブジェクト内部についての模式図で, FITS ファイルの内容のヘッダユニット・データユニットの内容が, 対応するクラスのオブジェクトで管理されています. 要するに, FITSファイルの内容がオブジェクトの構造に転写されている わけです.
次の表に,SFITSIO で使うクラスについての一覧を示します.
| クラス名 | fitscc オブジェクトからの引き出し方 | 表現している FITS 要素 |
|---|---|---|
| fitscc | - | FITS ファイルの全体 |
| fits_hdu | fits.hdu("HDU名") | FITS ファイルの HDU |
| fits_image (fits_hduを継承) | fits.image("HDU名") | FITS ファイルの Image HDU |
| fits_table (fits_hduを継承) | fits.table("HDU名") | FITS ファイルの Table HDU (Binary or ASCII Table) |
| fits_table_col | fits.table("HDU名").col("カラム名") | FITS ファイルの Table のカラム |
| fits_header | fits.hdu("HDU名").header() | FITS ファイルのヘッダユニット |
| fits_header_record | fits.hdu("HDU名").header("ヘッダキーワード") | FITS ファイルの1つのヘッダレコード |
FITS のデータ要素へのアクセスの例を示します:
printf("TELESCOP = %s\n",
fits.image("Primary").header("TELESCOP").svalue());
この場合,image("Primary") は
fits_image クラス
のオブジェクトを引き出し,header("TELESCOP") は
fits_header_record クラス
のオブジェクトを引き出しています.
最後の svalue() で
ヘッダ TELESCOP の文字列の値を取り出しています.
多くのヘッダレコードにアクセスする場合などには,
fits.image(... と書くと長いしパフォーマンスにも
良くありません.この場合は,参照を使って短く書く事ができます.
fits_image &img = fits.image("Primary");
printf("TELESCOP = %s\n", img.header("TELESCOP").svalue());
printf("GAIN = %g\n", img.header("GAIN").dvalue());
FITS ヘッダの値や,画像データのピクセル値などの, プリミティブなデータへのアクセスも, パターンが決まっているので,表にまとめておきます.
| メンバ関数名 | 機能 |
|---|---|
| dvalue() | 実数値 (double) の読み取り |
| lvalue() | 整数値 (long) の読み取り |
| bvalue() | 真理値 (bool) の読み取り |
| svalue() | 文字列 (const char *) の読み取り |
| assign() | 文字列,実数値,整数値,真理値の書き込み (メンバ関数のオーバロード) |
以上で FITS のほとんどのデータ要素へアクセスできるようになります. 代表的なものをまとめておきましょう.
| 目的のデータ要素へのアクセス | コードの例 |
|---|---|
| ヘッダの値の読み取り | fits.image("Primary").header("TELESCOP").svalue() |
| ヘッダの値の書き込み | fits.image("Primary").header("TELESCOP").assign("kp21m") |
| 画像のピクセル値の読み取り | fits.image("Primary").svalue(x,y,z) |
| 画像のピクセル値の書き込み | fits.image("Primary").assign(val,x,y,z) |
| テーブルのセル値の読み取り | fits.table("MY_TABLE").col("RA").dvalue(row_index) |
| テーブルのセル値の書き込み | fits.table("MY_TABLE").col("RA").assign(value,row_index) |
なお,dvalue(),assign() 等を使う方法では,
Image HDU の BZERO値,BSCALE値,BLANK値,
Binary Table HDU または ASCII Table HDU の
ZEROn値,TSCALn値,TNULLn値
が考慮され,ライブラリ側で変換処理が行なわれます
(lvalue()の場合は四捨五入された値を得ます).
SFITSIO では,
「fitscc オブジェクトの内容と目的のデータへのアクセス」
でみてきたクラスのほか,
型や型を示す整数値などの定数が
/usr/local/include/sli/fits.h
で定義されています.
ここでは,それらについてまとめておきます.
なお,これらの定数や型は,すべて namespace sli の中で定義されています.
例えば,「FITS::IMAGE_HDU」は完全な表記では
「sli::FITS::IMAGE_HDU」です.
| 型 | 定数 | 実際の値 | 意味 |
|---|---|---|---|
| int | FITS::ANY_HDU | 127 | 不明なタイプのHDU |
| int | FITS::IMAGE_HDU | 0 | Image HDU |
| int | FITS::BINARY_TABLE_HDU | 2 | Binary Table HDU |
| int | FITS::ASCII_TABLE_HDU | 1 | ASCII Table HDU |
| 型 | 定数 | 実際の値 | 意味 |
|---|---|---|---|
| long | FITS::ALL | longの最大値 | すべての配列要素 |
| long | FITS::INDEF | longの最小値 | 未定義を示す |
| 型 | 定数 | 実際の値 | 意味 |
|---|---|---|---|
| int | FITS::NULL_RECORD | 0 | すべてが空白文字である |
| int | FITS::NORMAL_RECORD | 1 | 「キーワード = 値 / コメント」の形式を示す |
| int | FITS::DESCRIPTION_RECORD | 2 | 「キーワード コメント」の形式を示す |
| 型 | 定数 | 実際の値 | 意味 | ヘッダ | Image | Binary Table |
|---|---|---|---|---|---|---|
| int | FITS::ANY_T | 127 | 不明な型 | |||
| int | FITS::ASCII_T | 65('A') | FITSの文字型(char型) | Yes | - | Yes |
| int | FITS::BIT_T | 88('X') | FITSのbit型 | - | - | Yes |
| int | FITS::LOGICAL_T | 76('L') | FITSの論理値型(unsigned char型) | Yes | - | Yes |
| int | FITS::BYTE_T | 66('B') | FITSの符号なし1バイト整数型(unsigned char型) | - | Yes | Yes |
| int | FITS::SHORT_T | 73('I') | FITSの2バイト整数型(16-bit整数型) | - | Yes | Yes |
| int | FITS::LONG_T | 74('J') | FITSの4バイト整数型(32-bit整数型) | - | Yes | Yes |
| int | FITS::LONGLONG_T | 75('K') | FITSの8バイト整数型(64-bit整数型) | Yes | Yes | Yes |
| int | FITS::FLOAT_T | 69('E') | float型 | - | Yes | Yes |
| int | FITS::DOUBLE_T | 68('D') | double型 | Yes | Yes | Yes |
| int | FITS::COMPLEX_T | 67('C') | FITSの複素数型(float _Complex型) | - | - | Yes |
| int | FITS::DOUBLECOMPLEX_T | 77('M') | FITSの倍精度複素数型(double _Complex型) | Yes | - | Yes |
| int | FITS::LONGARRDESC_T | 80('P') | 32-bit配列記述子(32-bit整数×2) | - | - | Yes |
| int | FITS::LLONGARRDESC_T | 81('Q') | 64-bit配列記述子(64-bit整数×2) | - | - | Yes |
| SFITSIOで使う型 | 実際の型 | Image | Binary Table |
|---|---|---|---|
| fits::ascii_t | char | - | Yes |
| fits::bit_t |
struct { unsigned char elem7:1; unsigned char elem6:1; unsigned char elem5:1; unsigned char elem4:1; unsigned char elem3:1; unsigned char elem2:1; unsigned char elem1:1; unsigned char elem0:1;}; |
- | Yes |
| fits::logical_t | uint8_t | - | Yes |
| fits::byte_t | uint8_t | Yes | Yes |
| fits::short_t | int16_t | Yes | Yes |
| fits::long_t | int32_t | Yes | Yes |
| fits::longlong_t | int64_t | Yes | Yes |
| fits::float_t | float | Yes | Yes |
| fits::double_t | double | Yes | Yes |
| fits::complex_t | float _Complex | - | Yes |
| fits::doublecomplex_t | double _Complex | - | Yes |
| fits::longarrdesc_t |
struct { uint32_t length; uint32_t offset;}; |
- | Yes |
| fits::llongarrdesc_t |
struct { uint64_t length; uint64_t offset;}; |
- | Yes |
| SFITSIOで使う型 | 実際の型 |
|---|---|
| fits::header_def |
struct { const char *keyword; const char *value; const char *comment;}; |
| SFITSIOで使う型 | 実際の型 |
|---|---|
| fits::table_def |
struct { const char *ttype; const char *ttype_comment; const char *talas; const char *telem; const char *tunit; const char *tunit_comment; const char *tdisp; const char *tform; const char *tdim; const char *tnull; const char *tzero; const char *tscal;}; |
では,実際に新しい FITS ファイルを作ってみましょう.
#include <stdio.h>
#include <sli/fitscc.h> /* required by every source that uses SFITSIO */
using namespace sli;
int main( int argc, char *argv[] )
{
fitscc fits; /* fitscc object that expresses a FITS file */
const long width = 300, height = 300; /* size of image */
long len_written, i;
/* fits オブジェクトに Primary HDU を追加 */
fits.append_image("Primary",0, FITS::SHORT_T, width,height);
fits_image &pri = fits.image("Primary");
/* ヘッダに "EXPOSURE" キーワードを追加 */
pri.header("EXPOSURE").assign(1500.).assign_comment("Total Exposure Time");
/* BZERO,BSCALE の設定と初期化 */
pri.assign_bzero(32768.0).assign_bscale(1.0).fill(0);
pri.assign_blank(65535);
pri.assign_bunit("ADU");
/* ピクセル値をセット */
for ( i=0 ; i < height ; i++ ) {
long j;
for ( j=0 ; j < width ; j++ ) pri.assign(j + i, j,i);
}
/* FITS ファイルを出力 */
len_written = fits.write_stream("testfile.fits");
printf("saved %ld bytes.\n", len_written);
if ( len_written < 0 ) return -1;
else return 0;
}
新規の Image HDU を作るには, fitsccクラス のオブジェクトを作って,
fits.append_image(HDU名,HDUバージョン, データ型, xの長さ,yの長さ,zの長さ);
とするだけで,あとは fitscc オブジェクトの内容と目的のデータへのアクセス で示したようにメンバ関数を使ってアクセスするだけです. ヘッダへのアクセスや,画像のピクセル値への高速アクセス などについては,この後で紹介します.
○実習23○
/usr/local/include/sli/fits.h
をみて,4バイト実数(float)型の新規データを作成するよう
コードを改造してください.
fits.append_image(…);」の直後に,
次のコードを挟んでコンパイルし,動作確認を行なってください.
fits::header_def defs[] = { {"TELESCOP", "'CASSIOPEIA'", "Telescope name"},
{"OBSERVAT", "'NAOJ'", "Observatory name"},
{"RA", "", "[deg] Target position"},
{"DEC", "", "[deg] Target position"},
{"COMMENT", "-------------------------------"},
{NULL} };
/* ヘッダの初期化 */
fits.image("Primary").header_init(defs);
画素の大きさは,
fits_imageクラスの
col_length(),
row_length(),
layer_length() で調べる事ができます.
例えば,画素の大きさを表示するには,次のように書けます.
fits_image &primary = fits.image("Primary");
printf("カラムの数 : %ld\n",primary.col_length());
printf("ロウの数 : %ld\n",primary.row_length());
printf("レイヤの数 : %ld\n",primary.layer_length());
読み出しには,
fits_imageクラスの
dvalue(),
lvalue(),
llvalue() のいずれかを使い,
書き込みには
assign()
を使います.
これらは,ヘッダの BZERO,BSCALE
の値による変換もやってくれます.
dvalue() を使うと,
イメージデータの型にかかわらず,doubleで読む事ができます.
座標値は 0-indexed です.
double pixel_val;
pixel_val = primary.dvalue(x,y,z); /* 読み */
primary.assign(pixel_val,x1,y1,z1); /* 書き */
もちろん,整数値で読み書きする事もできます.
lvalue(),llvalue()
でそれぞれ long,long long を返してくれます.
long pixel_val;
pixel_val = primary.lvalue(x,y,z); /* 読み */
primary.assign(pixel_val,x1,y1,z1); /* 書き */
dvalue() や assign()
は高いレベルのAPIですので安全性は
高いですが,その分呼び出しのオーバヘッドは小さくありません.
より高速なアクセスについてはこの後で紹介します.
オブジェクト内部データへのポインタ変数を使った高速アクセスも可能です.
ただし,
fits_imageクラス
の resize_2d()メンバ関数
を使った場合などで画素のサイズが変更になった場合は,データ配列のアドレスが変わ
るので注意が必要です.
高速アクセスのためには,値を読む時の
BZERO値とBSCALE値による変換がいらないように
内部データを変換してしまうと良いでしょう.
変換には,
fits_imageクラス
の convert_type()メンバ関数
を使います.例えば,次のようにします.
fits_image &primary = fits.image("Primary");
primary.convert_type(FITS::FLOAT_T);
以上で,どの形式のデータもBZERO値が0,BSCALE値が1のfloat型に変換されます. この後, fits_imageクラス の float_t_ptr_2d()メンバ関数,float_t_ptr()メンバ関数等 を使って,データのアドレスを得ます(それぞれの型に対応したメンバ関数があります).
fits::float_t *const *ptr_2d;
ptr_2d = primary.float_t_ptr_2d(true);
上記の場合は「ptr_2d[y][x]」の形で高速アクセスが可能です.
fits::float_t *ptr;
ptr = primary.float_t_ptr();
この場合は
「ptr[x + y * col_length]」の形でアクセスする事になります.
◎課題4◎
ヘッダへのアクセスへの基本はこれまでみてきたとおりです:
printf("TELESCOP = %s\n", fits.hdu("Primary").header("TELESCOP").svalue());
と書きます.HDUの指定は上記のように名前で指定するか,
数値(プライマリHDUの場合は「.hdu(0L)」)でもかまいません.
なお,この例では「fits.hdu(…)」と書いていますが,
これは HDU のタイプが不明な時の書き方です.
HDU のタイプがわかっている時は,
「fits.image(…)」と書いてもかまいません.
値の読み出しには
dvalue(),lvalue(),llvalue(),
bvalue(),svalue()
のいずれかを使います.
それぞれ,double,long,
long long,bool,const char *
の各型に対応します.
逆に,書き込む場合は,新規ヘッダレコード追加の場合も
値やコメントの更新の場合も,
assign() や assign_comment()
を使います.
fits.hdu("Primary").header("TELESCOP").assign("HST")
.assign_comment("Telescope Name");
fits.hdu("Primary").headerf("OBJECT%d",n).assignf("%s-%d",obj[i],j)
.assignf_comment("Name of the object No.%d",n);
のように書きます.LIBC の printf() 関数の書き方が
いたるところで使えるので,大変便利です.
HISTORY などの記述レコードの追加も簡単で,
header_append() メンバ関数に2つの引数を与え,
このように書きます:
fits.hdu("Primary").header_append("HISTORY","step-0: done.");
ヘッダのキーワードが存在し,値が存在するかどうかをチェックするには,
header_value_length()メンバ関数が便利です.
if ( 0 < fits.hdu("Primary").header_value_length("TELESCOP") ) {
/* OK */
}
このメンバ関数は,記述レコード以外から与えられたキーワードを検索し,
存在しない場合は負値,存在する場合はそのヘッダレコードの値の長さ
(文字列では「'」も含む)を返します.
ヘッダのキーワードと値が存在する事がわかったら,
値がどの型にあてはまるかをチェックしたい事もあります.
その場合は,type() を使います.
int r_type = fits.hdu("Primary").header("EQUINOX").type();
if ( r_type == FITS::DOUBLE_T ) {
/* 実数 */
} else if ( r_type == FITS::LONGLONG_T ) {
/* 整数 */
} else if ( r_type == FITS::DOUBLECOMPLEX_T ) {
/* 複素数 */
} else if ( r_type == FITS::LOGICAL_T ) {
/* 論理値 */
} else if ( r_type == FITS::ASCII_T ) {
/* 文字列 */
} else {
/* 予期せぬエラー */
}
なお,Primary HDUの場合は必ずイメージを扱うHDUですので,
fits.hdu(...) は fits.image(...)
としてもかまいません.
s++ コマンドで表示されるのサンプルコードもご覧ください.
ヘッダの初期化(header_init()),
ヘッダレコードの追加(header_append_records()),
挿入(header_insert_records()),
削除(header_erase_records())
を行なうメンバ関数が
fits_hduクラス
で用意されています
(fits_imageクラス
や
fits_tableクラス
は
fits_hduクラス
を継承しているので,同様に使えます).
次のコードは,一方のFITSのヘッダレコードのすべての内容を, もう1方にコピーする例です.
fits_out.image("Primary")
.header_append_records( fits_in.image("Primary").header() );
このように,引数が無い形 .header() は,ヘッダ全体を表現しており,同様にして,
header_init()メンバ関数,
header_insert_records()メンバ関数
に与える事ができます.
ヘッダレコードのすべての内容ではなく, 1つのヘッダレコードをコピーする場合は,次のようにします.
fits_out.image("Primary")
.header_append( fits_in.image("Primary").header("TELESCOP") );
以下に,既存の FITS ファイルのヘッダを,新規 FITS ファイルに コピーするコードを示します. 「IRAF の imcopy を作る」 のコードを少し手直ししただけです.
#include <sli/stdstreamio.h>
#include <sli/fitscc.h> /* SFITSIO 使用時はこれを includeすればOK */
using namespace sli;
int main( int argc, char *argv[] )
{
int return_status = -1;
stdstreamio sio; /* standard I/O */
fitscc in_fits; /* FITS object (in) */
/* FITS ファイルを読む */
if ( 1 < argc ) {
const char *in_file = argv[1];
if ( in_fits.read_stream(in_file) < 0 ) {
sio.eprintf("[ERROR] in_fits.read_stream(\"%s\") failed\n",in_file);
goto quit;
}
}
/* ヘッダをコピーした新規 FITSファイルを作成 */
if ( 2 < argc ) {
const char *out_file = argv[2];
fitscc out_fits; /* FITS object (out) */
const fits_image &in_img = in_fits.image("Primary");
out_fits.append_image(in_img.extname(), in_img.extver(), FITS::FLOAT_T,
in_img.col_length(), in_img.row_length());
out_fits.image("Primary")
.header_append_records( in_img.header() );
if ( out_fits.write_stream(out_file) < 0 ) {
sio.eprintf("[ERROR] out_fits.write_stream(\"%s\") failed\n",out_file);
goto quit;
}
}
return_status = 0;
quit:
return return_status;
}
オブジェクト指向の特徴は,このように それぞれのオブジェクトが FITS の部品を表現していて, メンバ関数を使って部品単位で編集ができるという事です.
○実習24○
上記のコードをコンパイルし,動作を確認してください.
元の FITS ファイルは
M83_DSS2_R_A2EE.fits.gz
を利用してください.
なお,標準エラー出力に警告が出ますが,新しいバージョンの SFITSIO では
header_append_records() に
警告を報告しないようにするオプションを追加する予定です.
fits_imageクラス
には
IDL/Python風の表記を使って矩形の領域のコピーとペーストを行なうためのメンバ関数,
copyf() と pastef() が用意されています.
次に示すのは,座標(0,0)から(99,99)までの矩形領域を,
座標(100,100)へコピーする例です.
fits_image &primary = fits.image("Primary");
fits_image copy_buf;
primary.copyf(©_buf, "0:99, 0:99");
primary.pastef(copy_buf, "100:*, 100:*");
プログラマが作った
fits_image
のオブジェクト copy_buf を
コピーバッファとして使っています.
その copy_buf オブジェクトをメンバ関数に与えて,
コピー & ペーストを行ないます.
コピーバッファはいくつでも持つ事ができますし,
オブジェクト間のコピー & ペーストも簡単です.
pastef() のかわりに addf(),subtractf(),
multiplyf(),dividef() を使うと,
足し算,引き算,掛け算,割り算もできます.
速度が重視される本格的な画像解析ツールを開発する場合には, SLLIB の単純な実装によるAPIを使ってコーディングを行なう事で, 全体的なパフォーマンスアップが可能です.
次に SLLIB ベースの解析を行なう手順を述べます. 考え方としては,IDL や Python + numpy の場合と同様, FITSの画像データを単純な配列オブジェクトとして プロセッシングを行なうというものです.
まず,FITSファイルを読み,データ型をfloat型またはdouble型に変換します.
fitscc fits;
fits.read_stream("largefile.fits");
fits_image &prim = fits.image(0L);
prim.convert_type(FITS::FLOAT_T);
次に, mdarray_floatクラス で参照を取得します.
mdarray_float &prim_arr = prim.float_array();
この後,配列に対しては SLLIB の mdarray クラスの API を使い, FITSヘッダに対しては SFITSIO の API を使います. 例えば,ゲインをかけて画像の一部の 統計をとるには 次のように書けます.
double gain = prim.header("GAIN").dvalue();
prim_arr *= gain;
double meanabsdev, stddev;
/* get mean, variance, skewness, kurtosis, and stddev */
mdarray_double moment = md_moment(prim_arr.sectionf("2:21, *"), false,
&meanabsdev, &stddev);
printf("mean = %g\n", moment[0]);
printf("variance = %g\n", moment[1]);
printf("skewness = %g\n", moment[2]);
printf("kurtosis = %g\n", moment[3]);
printf("meanabsdev = %g\n", meanabsdev);
printf("stddev = %g\n", stddev);
なお,SLLIB は FITS とは無関係なライブラリなので, プリミティブ型の名称が SFITSIO の場合とは異なります. 次に対応関係を示します.
| 用途 | SFITSIOでの型 | SLLIBでの型 |
|---|---|---|
| 画像サイズの大きさを表現する型 | long | size_t |
| 実数型 | fits::float_t fits::double_t | float double |
| 整数型 | fits::byte_t fits::short_t fits::long_t fits::longlong_t | unsigned char int16_t int32_t int64_t |
◎課題5◎
WCSTools (http://tdc-www.harvard.edu/wcstools/) は WCS (World Coordinate System) をはじめとした, 天文学のデータを効率良く扱うために開発されたC言語ライブラリです. FITSファイルや天体カタログファイルにも対応しており, SAO の Douglas J. Mink 氏が開発・メンテナンスしています.
ここでは,SFITSIOをlibwcsと組み合わせると, 簡単にWCSを扱える事を示してみます.
コードの例を示します.始めに,引数で指定された
FITSファイルを読み込み,
wcsinitn()関数を使って,
プライマリHDUについて,FITSヘッダから WorldCoor構造体の
オブジェクトを wcsに作成しています.
この時に,プライマリHDUのすべてのヘッダレコードを1つの文字列として返して
header_formatted_string()メンバ関数
を利用しています.
次の iswcs() 関数では,
WorldCoor構造体のオブジェクトが正しくセットされたか
どうかをチェックしています
(iswcs()関数は,正しくセットされた場合は1,そうでない場合は
0を返します).
その後,pix2wcs()関数を使ってピクセル座標(0,0)について
世界座標(lon, lat)を求め,
さらに wcs2pix() 関数で逆の変換をしています.
最後に当該ピクセルの値を表示し,wcs
が使っているメモリを開放しています.
#include <sli/stdstreamio.h>
#include <sli/fitscc.h>
#include <math.h>
#include <libwcs/wcs.h>
using namespace sli;
int main( int argc, char *argv[] )
{
int ret_status = -1;
stdstreamio sio;
fitscc fits; /* FITS object */
struct WorldCoor *wcs = NULL; /* WCS structure */
double lon,lat, x,y, v;
int off;
if ( 1 < argc ) {
const char *in_file = argv[1];
/* FITSファイルを読む */
if ( fits.read_stream(in_file) < 0 ) {
sio.eprintf("[ERROR] fits.read_stream(\"%s\") failed\n",in_file);
goto quit;
}
/* Primary HDU を示すオブジェクトへの参照の作成 */
fits_image &pri = fits.image("Primary");
/* wcs 構造体のオブジェクトを取得する */
wcs = wcsinitn(pri.header_formatted_string(), NULL);
if ( ! iswcs(wcs) ) {
sio.eprintf("[ERROR] wcsinitn() failed\n");
goto quit;
}
/* ピクセル座標 -> wcs の変換 */
x = 1.0; y = 1.0;
pix2wcs(wcs, x, y, &lon, &lat);
sio.printf("ra=%.8f dec=%.8f\n",lon,lat);
/* wcs -> ピクセル座標 の変換 */
wcs2pix(wcs, lon, lat, &x, &y, &off);
sio.printf("x=%.8f y=%.8f\n",x,y);
/* ピクセル値を読む (1-indexed) */
v = pri.dvalue((long)floor(x-0.5),(long)floor(y-0.5));
sio.printf("value=%.15g\n",v);
}
ret_status = 0;
quit:
/* wcs 構造体のオブジェクトを開放 */
if ( wcs != NULL ) wcsfree(wcs);
return ret_status;
}
WCSToolsのこれ以上の情報については,ヘッダファイル wcs.h
等を参照してください.
WCSToolsのヘッダファイルには,かなりしっかりとコメントが記載されており,
それらを読むだけでもかなりの事ができるようになるはずです.
○実習25○
次の手順で,上記のコードを動かしてみてください.
$ tar zxvf wcstools-3.8.7.tar.gz $ cd wcstools-3.8.7/libwcs $ make CFLAGS="-O -Wall" $ cd ../..
$ s++ -Iwcstools-3.8.7 wcs_sample.cc wcstools-3.8.7/libwcs/libwcs.a -lsfitsio
「fitscc オブジェクトの内容と目的のデータへのアクセス」 で示したように,バイナリテーブルへのアクセスも 「なんとか.なんとか.なんとか」の形をとります:
double value = fits.table("MY_TABLE").col("RA").dvalue(row_index);
fits.table("MY_TABLE").col("RA").assign(value, row_index);
新規のバイナリテーブルを作成する場合は,次のように 構造体を使う方法があります:
fitscc fits;
const fits::table_def def[] = {
/* ttype,comment, talas,telem,tunit,comment, */
/* tdisp, tform, tdim, tnull */
{ "TIME","satellite time", "", "", "s","", "F16.3", "1D", "" },
{ "STATUS","status", "", "", "","", "", "8J", "", "-99999" },
{ "NAME","", "", "", "","", "", "128A16", "(4,2)" },
{ NULL }
};
/* バイナリテーブルの作成(HDU名は"EVENT") */
fits.append_table("EVENT",0, def);
しかし,SFITSIO は「FITSテンプレート」という機能を持ち, それを使う方が様々な応用が効くのでお勧めです. FITSテンプレートとは, FITSヘッダに類似した曖昧な文法でFITSの内容を定義できるテキスト形式のファイルで, これをもとにデータが入っていない新規 FITSファイル(オブジェクト)を 作成する事ができます. 例えば,上記の構造体で定義されたバイナリテーブルを, FITSテンプレートで書くと次のようになります.
XTENSION = BINTABLE EXTNAME = EVENT TTYPE# = 'TIME' / satellite time TFORM# = '1D' TUNIT# = 's' TDISP# = 'F16.3' TTYPE# = STATUS / status TFORM# = '8J' TNULL# = -99999 TTYPE# = 'NAME' TFORM# = '128A16' TDIM# = '(4,2)'
一方,コードは
read_stream()
のかわりに,
read_template()
を使うだけです.
#include <sli/stdstreamio.h>
#include <sli/fitscc.h>
using namespace sli;
int main( int argc, char *argv[] )
{
int return_status = -1;
stdstreamio sio;
fitscc fits;
if ( 1 < argc ) {
const char *templ_filename = argv[1];
/* FITS テンプレートを読み取る */
if ( fits.read_template(templ_filename) < 0 ) {
sio.eprintf("[ERROR] fits.read_template() failed\n");
goto quit;
}
if ( fits.hdutype(1L) == FITS::BINARY_TABLE_HDU ) {
long i, j;
/* テーブルオブジェクトへの参照を取得 */
fits_table &tbl = fits.table(1L);
/* カラムオブジェクトへの参照を取得 */
fits_table_col &col_time = tbl.col("TIME");
fits_table_col &col_name = tbl.col("NAME");
/* すべてのセルを NULL 値に初期化 */
for ( i=0 ; i < tbl.col_length() ; i++ ) {
tbl.col(i).assign_default(NAN);
}
/* 行を確保 */
tbl.resize_rows(64);
#if 0
/* セルに値をセット */
for ( i=0 ; i < tbl.row_length() ; i++ ) {
col_time.assign(1000 + i, i);
for ( j=0 ; j < col_name.elem_length() ; j++ ) {
col_name.assign("None", i, j);
}
}
#endif
}
}
if ( 2 < argc ) {
const char *out_filename = argv[2];
sio.printf("# writing ...\n");
if ( fits.write_stream(out_filename) < 0 ) {
sio.eprintf("[ERROR] fits.write_stream() failed\n");
goto quit;
}
}
return_status = 0;
quit:
return return_status;
}
○実習26○
#if 0」を「#if 1」にして動作させ,
値がセットされている事を確認してください.
これまでみてきたように,SFITSIO はオンメモリ型の FITS I/O が基本です.
また,ファイル名直後の […] の表現でディスクベースでの
"部分読み"もできるので,ゴミがついているファイルや
巨大なファイルでも読み取りは可能です.
しかし,場合によっては,ヘッダのみを高速に読み取りたい事や, ディスク上の画像データにランダムにアクセスしたい事もあります. SFITSIO ではそのような事も想定し, SLLIB でオープンしたストリームに対して, ヘッダユニット,データユニットにアクセスするための API を 提供しています.
最も簡単な例として,ヘッダ部分のみ読むコードを示します. このコードは,ヘッダの部分だけをストリームから読み,ストリームを閉じるので, たとえ圧縮ファイルであっても, ネットワーク上のファイルであっても, 非常に高速に動作します. ポイントは fits_headerクラス のメンバ関数を利用する事です.
#include <sli/stdstreamio.h>
#include <sli/digeststreamio.h>
#include <sli/fitscc.h>
using namespace sli;
int main( int argc, char *argv[] )
{
int ret_status = -1;
stdstreamio sio;
digeststreamio f_in;
if ( 1 < argc ) {
const char *in_file = argv[1];
fits_header hdr; /* ヘッダオブジェクト */
/* ストリームをオープン */
if ( f_in.open("r", in_file) < 0 ) {
sio.eprintf("[ERROR] cannot open file: %s\n",in_file);
goto quit;
}
/* Primary HDU のヘッダを読む */
hdr.read_stream(f_in);
/* ヘッダの内容を表示 */
sio.printf("BITPIX = %ld\n", hdr.at("BITPIX").lvalue());
long naxis = hdr.at("NAXIS").lvalue();
long i;
for ( i=0 ; i < naxis ; i++ ) {
tstring key;
key.printf("NAXIS%ld",i+1);
sio.printf("%s = %ld\n", key.cstr(), hdr.at(key.cstr()).lvalue());
}
sio.printf("TELESCOP = %s\n", hdr.at("TELESCOP").svalue());
sio.printf("DATE-OBS = %s\n", hdr.at("DATE-OBS").svalue());
sio.printf("\n");
sio.printf("[all string]\n");
sio.printf("%s\n", hdr.formatted_string());
}
ret_status = 0;
quit:
return ret_status;
}
「hdr.read_stream(f_in);」
の時点でファイルポインタは次のData Unitの先頭にあるので,
f_in.read(...)
などで Data Unit にアクセスが可能です.
その場合,
fits_headerクラス
のオブジェクト hdr は
Primary HDUの全ヘッダの内容を保持していますから,
NAXIS1,NAXIS2 等の値の取得も簡単です.
Data Unit の読み飛ばしも簡単です (ただし,ここは圧縮ファイルだと速度は出ません):
hdr.skip_data_stream(f_in);
このようにすると,hdr オブジェクトに入っている
ヘッダ情報に基づいて Data Unit 部分をスキップします.
次の HDU のヘッダも同様に読み取りができます.
hdr.read_stream(f_in);
必要なものを読んだら,いつでもストリームをクローズしてOKです.
f_in.close();